Best Practices for Anonymizing Contact Data
How to anonymize emails, phone numbers, and addresses while keeping data useful—covering masking, tokenization, differential privacy, testing, and compliance.

Anonymizing contact data is critical for protecting privacy while maintaining data usability. Businesses often handle sensitive information like emails, phone numbers, and addresses, making robust anonymization essential to avoid risks like data breaches and regulatory penalties. Here's what you need to know:
- Why it matters: In 2024, data breaches involving test environments cost companies $14.82M on average, with 87% linked to poor anonymization practices. Regulations like GDPR and CCPA mandate strict privacy measures.
- Challenges: Striking a balance between privacy and usability is tough. Over-anonymizing can make data unusable, while under-anonymizing leaves it vulnerable. Unstructured data like emails and chat logs often hide sensitive information, complicating protection efforts.
- Key methods:
- Suppression: Remove sensitive data entirely.
- Generalization: Reduce detail (e.g., using age ranges instead of exact birthdates).
- Masking: Hide real values while maintaining data structure.
- Pseudonymization: Replace identifiers with reversible tokens.
- Differential Privacy: Add noise to data to prevent re-identification.
- Testing for risks: Use techniques like k-anonymity and re-identification risk scoring to ensure anonymized data is secure.
To implement these practices, classify data by sensitivity, select appropriate anonymization methods, and continuously monitor compliance. Tools like Enrichfox.ai and K2view can help manage and protect data efficiently.
What Are The Best Data Anonymization Techniques? - AI and Technology Law
Methods for Anonymizing Contact Data
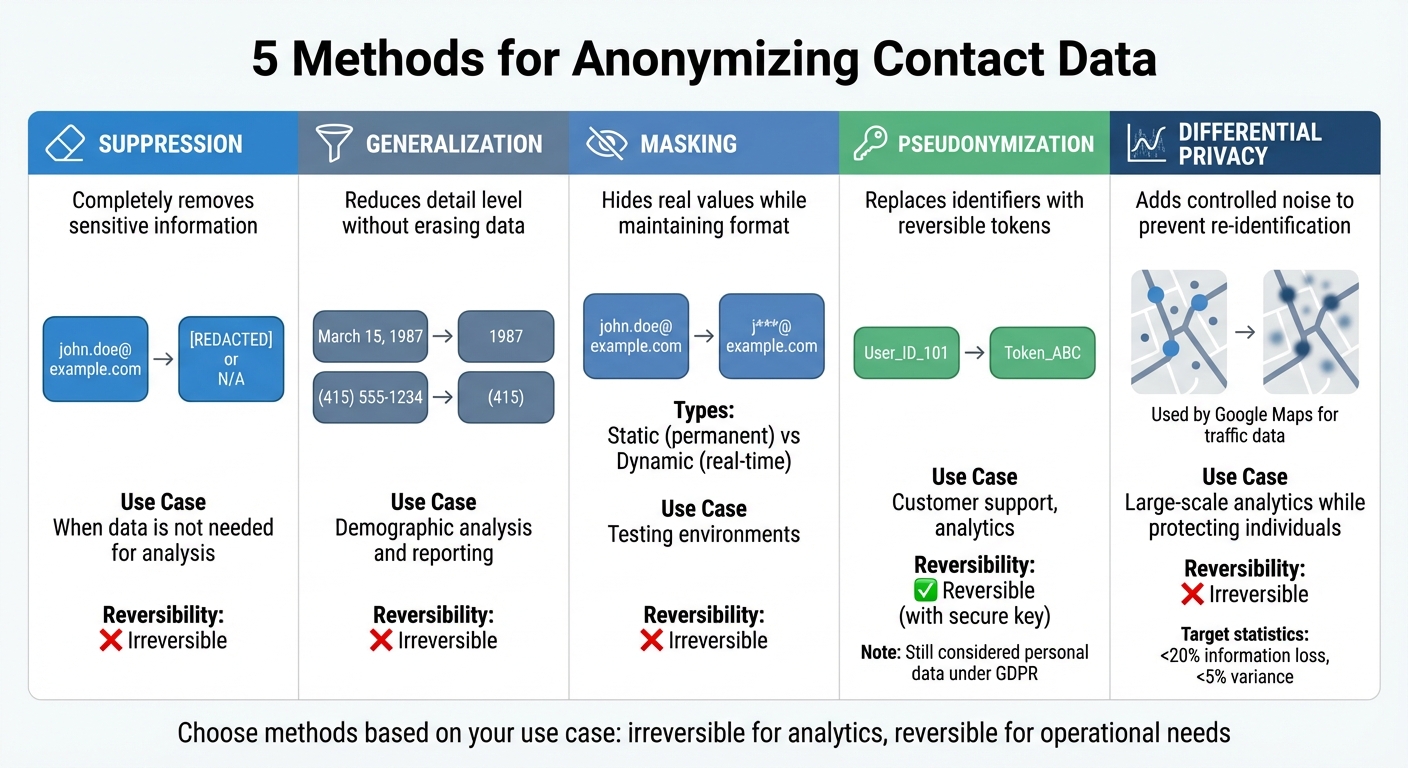
Contact Data Anonymization Methods Comparison Chart
Anonymizing data is a way to protect privacy while still keeping the data useful for purposes like marketing, testing, or analytics.
Data Suppression, Generalization, and Masking
Suppression involves completely removing sensitive information from a dataset. This can be done by redacting details (blacking out information) or replacing fields with placeholders like "N/A" or empty values.
Generalization reduces the level of detail in the data without erasing it. For instance, instead of storing an exact birth date like "March 15, 1987", you might only keep the birth year, "1987." Similarly, phone numbers could be shortened to just the area code (e.g., "(415)" instead of "(415) 555-1234"), and email addresses can be partially obscured (e.g., "j***@example.com" instead of "john.doe@example.com").
Data masking hides the real values but keeps the data format intact. This is especially useful in testing environments where data needs to maintain a specific structure. There are two main types:
- Static masking creates a permanent masked version for non-production use.
- Dynamic masking applies rules in real-time during queries, so unauthorized users only see the masked data while the original remains untouched.
For added flexibility, some methods allow controlled reversibility, making it possible to access the original data when necessary.
Pseudonymization and Tokenization
Pseudonymization and tokenization replace real identifiers with placeholders (tokens) that can be reversed using a secure key or token vault. For example, customer support systems might use tokens to track user interactions without exposing actual names or contact details. A well-known example is the NHS, which uses this approach to share health data with researchers while ensuring patient privacy under GDPR guidelines.
Format-preserving encryption (FPE) is another method that encrypts data while keeping its original structure. A phone number, for example, remains a 10-digit number, and an encrypted email address still looks like an email address. Unlike basic masking, FPE uses cryptographic algorithms, providing stronger security.
When using reversible techniques, it’s crucial to maintain referential integrity. For example, if "User_ID_101" is replaced with "Token_ABC" in one table, the same replacement must occur in all related tables (like Users and Orders) to keep the data usable for analysis.
After implementing these methods, it’s essential to test the anonymization to ensure it holds up against re-identification attempts.
Testing for Re-identification Risks
Even anonymized data can sometimes be traced back to individuals. This risk often comes from quasi-identifiers - data points that seem harmless on their own but, when combined, can uniquely identify someone.
Start by calculating a Re-identification Risk Score to measure how easily anonymized records could be linked back to real individuals. Privacy models like k-anonymity can help mitigate this risk by ensuring that each record is indistinguishable from at least k-1 others. For instance, if k=5, every record must match at least four others in the dataset.
Another effective method is differential privacy, which introduces controlled noise into the data. This technique, used by tools like Google Maps, ensures overall trends (like traffic flow or popular destinations) remain accurate while preventing individual data points from being traced back to specific people. A well-anonymized dataset typically aims for less than 20% information loss and a variance of under 5% between original and anonymized metrics.
Finally, test your methods by attempting to re-identify individuals in the dataset. Compare the anonymized data with publicly available records - like social media profiles, voter lists, or property databases - to ensure that no combination of data points (e.g., job title and company name) can inadvertently expose someone’s identity.
This type of testing ensures that anonymized data remains secure while still being practical for analysis and other uses. It strikes a balance between privacy and utility.
How to Implement Anonymization in Your Business
Building on established anonymization techniques, implementing these practices ensures both robust privacy and operational insight.
Classifying Data by Sensitivity Level
Before you can anonymize data, you first need to pinpoint what requires protection. Start by identifying all systems that store contact data - this includes SaaS apps, databases, and on-premises servers. Don't overlook Shadow IT data stores, which are often created outside official systems.
Next, create clear classification tiers. A straightforward three-level model works well: Low (public information), Moderate (standard business contacts), and High (sensitive identifiers). Sensitivity is highly context-dependent. As Alex Hayward, Co-Founder of GoMask.ai, points out:
"Context determines sensitivity. A zip code might seem harmless, but combined with a birth date and gender, it can identify 87% of the U.S. population."
Differentiate between direct identifiers (like names, emails, phone numbers, or Social Security numbers), quasi-identifiers (such as ZIP codes, birth dates, genders, or job titles), and sensitive attributes (e.g., health records, financial history, or precise geolocation). For example, a name on its own might be low to moderate risk, but in a medical context, it becomes high-risk Protected Health Information under HIPAA.
Leverage AI-powered tools for contact data accuracy and natural language processing to locate sensitive data in unstructured fields like chat logs, emails, or JSON blobs. Label data at the column or file level so its classification remains intact throughout its lifecycle.
Once you've classified the data, select anonymization techniques that protect sensitive details while preserving the data's value.
Maintaining Data Usefulness After Anonymization
After defining sensitivity levels, it's essential to tailor anonymization methods to maintain the data's usefulness. Anonymization often involves a trade-off between privacy and usability. The key is choosing the right approach for each scenario. For example:
- Pseudonymization: This technique replaces direct identifiers with tokens, making it ideal for analytics and machine learning while preserving statistical accuracy. Under GDPR, fully anonymized data is no longer considered personal data, meaning it can be stored and used indefinitely without explicit consent.
- Generalization: For demographic marketing and research, generalizing data (e.g., replacing exact ages with ranges like 30–40 or summarizing addresses by city) offers broad insights while protecting individual details.
- Synthetic Data Generation: When testing software or training AI models, synthetic data can mimic real-world patterns without using actual records.
Anonymization alone isn't enough. Combine it with other measures like RBAC (Role-Based Access Control), encryption, and dynamic masking. This layered approach is especially important for B2B contact enrichment, where job titles and email addresses frequently change - job titles can shift by 30–35% annually, and email addresses may decay at rates of 25–30%. Regular audits, such as testing for re-identification risks by cross-referencing anonymized datasets with public records, are also crucial. For instance, in a dataset of 1.5 million individuals, just four spatio-temporal points can uniquely identify 95% of people.
Updating Processes and Monitoring Compliance
Anonymization isn't a one-and-done task - it requires continuous monitoring to address "data drift" and ensure compliance over time. Statistics show that 87% of data breaches involve test environments, and 73% of organizations still use production data in testing with minimal anonymization.
Set up a continuous discovery cycle to regularly scan data repositories and detect changes as new SaaS apps and AI workflows are introduced. A phased 90-day roadmap can help streamline the process: spend 30 days assessing your environment, 30 days piloting your approach, and 30 days rolling it out across the organization. Store encryption keys, salts, and token vaults in secure, restricted environments like HSM (Hardware Security Modules) or KMS (Key Management Systems).
Integrate anonymization directly into CI/CD pipelines so data is automatically protected before leaving production systems. Track metrics like the Re-identification Risk Score (aim for less than 0.05% for high-risk data) and the K-Anonymity Level (target k ≥ 10 for sensitive datasets). Maintain detailed evidence logs, such as Data Protection Impact Assessments and Records of Processing Activities, to demonstrate compliance during audits.
Consider using established tools to simplify the process. For example, IBM Guardium provides monitoring and alerts for large enterprises, ARX offers open-source risk analysis, and platforms like Gigantics help maintain referential integrity by consistently masking original identifiers across relational databases.
Comparing Contact Data Management Tools
When managing contact data, it's important to find tools that combine advanced anonymization methods with effective enrichment capabilities. After ensuring data is anonymized, focus on platforms that integrate enrichment features with strong privacy safeguards.
Features to Look for in Data Management Tools
When assessing contact data management solutions, prioritize platforms offering multiple anonymization techniques. These might include data masking, pseudonymization, synthetic data generation, and generalization. A critical feature is detection accuracy - your tool should reliably identify sensitive information across both structured databases and unstructured formats like chat logs or JSON files. Maintaining data relationships is another key aspect, so look for options with configurable anonymization policies and audit logs to enhance compliance.
Processing speed and scalability are non-negotiable. Inefficient tools can cost organizations an average of $12.9 million annually, so it's essential to choose a solution that handles large data volumes without delays. On-premise platforms often provide the highest levels of security and compliance, while cloud-based options deliver added convenience.
For contact enrichment, waterfall enrichment - layering multiple data sources - can significantly improve match rates. This is particularly crucial since B2B contact data decays at rates ranging from 22.5% to 70% annually. Companies that enrich and properly manage their customer data can achieve up to 40% higher marketing ROI.
The table below compares some of the leading platforms based on these criteria.
Tool Comparison Table
Here’s how some of the top platforms perform in contact data management and anonymization:
| Tool | Best For | Key Privacy Features | Pricing | G2 Rating |
|---|---|---|---|---|
| Enrichfox.ai | Cost-effective data enrichment | Email validation, bulk enrichment, API/webhook integration | $0.00025 per verified email; $0.05 per email found; $0.03 per phone | N/A |
| Apollo.io | Sales teams | Waterfall enrichment, buyer intent signals, free tier | Free tier; paid plans starting at $49/month | 4.8/5 |
| ZoomInfo | Enterprise B2B | Large-scale database, automated CRM maintenance | $15,000–$50,000+ per year | 4.4/5 |
| K2view | Large enterprises | Entity-based micro-database approach, real-time masking | Custom enterprise pricing | 4.5/5 |
| Gallio PRO | GDPR compliance | High detection accuracy, on-premise processing, API-first | Custom pricing | N/A |
| Cognism | European markets | Custom enterprise compliance features | $15,000–$30,000 per year | 4.6/5 |
Enrichfox.ai shines with its highly competitive pricing - just $0.00025 per verified email - making it a great choice for businesses handling large volumes of data on a budget. It offers 99% email validation accuracy, bulk enrichment, API integrations, and CSV export capabilities, all without the hefty price tag of some enterprise-grade tools.
For workflows focused on anonymization, K2view stands out with its entity-based micro-database approach. This method manages data on a per-business-entity basis, reducing privacy risks compared to traditional bulk anonymization techniques. Similarly, Gallio PRO is an excellent option for GDPR compliance, offering precise detection and complete on-premise processing.
Striking the right balance between data enrichment and privacy is critical. In 2024, U.S. data breaches exposed an average of 760,000 records daily, impacting 277 million individuals. These tools help implement best practices for data protection while enabling effective contact enrichment, ensuring organizations stay both secure and efficient.
Conclusion and Recommendations
Summary of Key Points
To safeguard contact data effectively, it's crucial to distinguish between anonymization and pseudonymization. Anonymization is a one-way process, making data untraceable to individuals, while pseudonymization involves reversible methods like tokenization, which can allow re-identification under controlled conditions. Under GDPR, pseudonymized data is still classified as personal data. For workflows like customer support, where re-identification may be necessary, reversible techniques such as tokenization are ideal. On the other hand, irreversible methods like k-anonymity or differential privacy work well for analytics and reporting purposes.
Striking the right balance between privacy and utility is essential. Overdoing anonymization can strip data of its business value, while insufficient protection increases the risk of breaches, which cost an average of $183 per compromised customer record. For instance, a multinational B2B team improved data privacy by replacing raw emails with salted hashes and storing IDs in a tokenization vault. By integrating differential privacy, they cut DSAR fulfillment time by 62% within two quarters, all while maintaining data usability.
Key management is another critical aspect. Store encryption keys, salts, and token vaults separately using secure solutions like HSM (Hardware Security Modules) or KMS (Key Management Services), and rotate these regularly. Continuously test for re-identification risks using metrics like k-anonymity (aiming for k≥5) and simulate linkage attacks as new data is added.
With these principles in mind, businesses can take actionable steps to protect their data while maintaining its value.
Action Steps for Your Business
To implement a strong data protection framework, consider a 90-day plan:
- Days 1–30: Conduct a thorough audit and classification of your data.
- Days 31–60: Deploy privacy tools and configure policies tailored to your needs.
- Days 61–90: Integrate these processes into CI/CD pipelines and establish systems for continuous monitoring.
Select tools that balance data enrichment with privacy. For example, Enrichfox.ai delivers email validation and bulk enrichment with 99% accuracy, making it a cost-effective choice for high-volume operations. For businesses requiring advanced anonymization, look for platforms that support secure, on-premise processing. Automate enrichment workflows using waterfall methods that query multiple providers to achieve 85–95% data coverage. Additionally, refresh your contact database every 30–90 days to counter the 25–30% annual email decay rate.
Finally, ensure compliance by documenting every anonymization decision, parameter, and outcome. This level of transparency is essential for passing audits under GDPR, CCPA, or ISO 27701. By taking these steps, you can protect sensitive data while preserving its business value.
FAQs
How do I choose between anonymization and pseudonymization?
Anonymization eliminates all personal identifiers from data, making it impossible to trace back to individuals. This method is perfect for scenarios requiring irreversible privacy protection, such as sharing data for research.
On the other hand, pseudonymization swaps personal identifiers with pseudonyms, allowing the data to be re-identified but only under strict safeguards. This approach works well for purposes like analytics or operational tasks where some level of controlled re-identification is necessary.
Use anonymization when data privacy must be permanent, and opt for pseudonymization when reversible data use is required within a secure framework.
What’s the safest way to anonymize contact data for testing environments?
The best approach to anonymizing contact data for testing involves methods that safeguard privacy without compromising the data's usefulness. Here are three key techniques:
- Data masking: This method swaps out sensitive information with realistic but non-sensitive substitutes, ensuring that the data looks authentic without revealing actual details.
- Pseudonymization: By replacing identifiers with reversible tokens, this technique prevents direct identification while allowing data to remain functional for certain tasks.
- Data minimization: This involves keeping only the essential fields necessary for testing, significantly lowering the risk of exposing sensitive information.
Using a combination of these techniques helps meet privacy regulations like GDPR and CCPA while preserving the data's integrity for testing purposes.
How can I measure re-identification risk after anonymizing data?
To assess re-identification risk, it's essential to analyze how quasi-identifiers - like birth date, ZIP code, or gender - could potentially lead to identifying individuals. Tools such as ARX or Google Cloud's Sensitive Data Protection can be used to simulate linkage attacks and examine data uniqueness. These simulations provide a way to estimate the likelihood of re-identification, ensuring your privacy measures are working as intended.